从基于领域方法到LFM
领域方法
UserCF(基于用户的协同过滤)
基于用户的协同过滤,主要是比较与目标用户的兴趣类似的用户(对于数值的特征,直接采用余弦相似度;对于“类”的特征,则可以先进行one-hot之后进行余弦相似度),然后将这些用户有过行为的物品推荐给目标用户
class UserCF:
def __init__(self):
self.file_path = 'dataset/ratings.csv'
self.df = pd.read_csv(self.file_path)
@staticmethod
def _cosine_similarity(vector1, vector2):
"""
因为MovieId大小不是量,而是代表类, 这里的余弦相似就是进行了一个类似于 hashmap 的操作
所以用len来带入了cosine_similarity操作
simple method for calculate cosine distance.
e.g: x = [1 0 1 1 0], y = [0 1 1 0 1]
cosine = (x1*y1+x2*y2+...) / [sqrt(x1^2+x2^2+...) * sqrt(y1^2+y2^2+...)]
that means union_len(movies1, movies2) / sqrt(len(movies1)*len(movies2))
"""
union_len = len(set(vector1) & set(vector2)) # 等价于x1*y1+x2*y2+...
if union_len == 0:
return 0.0
product = len(vector1) * len(vector2) # 等价于sqrt(x1^2+x2^2+...) * sqrt(y1^2+y2^2+...)
cosine = union_len / np.sqrt(product)
return cosine
def get_top_n_users(self, target_user_id, top_n):
"""
get top n users that similar to target_user
获取与target_user_id最相似的top_n个用户
依据的是用户点评过的电影的相似度
:param target_user_id:
:param top_n:
:return: top n users, similarity
"""
target_movies = self.df[self.df['UserId'] == target_user_id]['MovieId'].unique() # target用户点评过的电影
# print('target_movies: ', target_movies)
other_user_ids = self.df[self.df['UserId'] != target_user_id]['UserId'].unique() # target之外的其他用户
# print('other_user_ids: ', other_user_ids)
other_movies = [self.df[self.df['UserId'] == userid]['MovieId'].unique() for userid in other_user_ids] # 其他用户点评过的电影
# print('other_movies: ', other_movies)
sim_list = [self._cosine_similarity(target_movies, movies) for movies in other_movies]
sim_list = sorted(zip(other_user_ids, sim_list), key=lambda x: x[1], reverse=True) # zip打包成元组: (userid, sim) 即userid 和 target_user_id的相似度
return sim_list[:top_n]
def get_top_n_movies(self, top_n_users, candidates_movies, top_n):
"""
calculate interest of candidates movies and return top n movies
计算候选电影的兴趣度并返回top n电影
:param top_n_users:
:param candidates_movies:
:param top_n:
:return: top_n_movies
"""
top_n_user_data = [self.df[self.df['UserId'] == userid] for userid, _ in top_n_users] # 得到之前相似前top_n个用户的数据, 一个df的list
interest_list = []
for movie in candidates_movies: # 选一个候选的movies
temp = []
for user_data in top_n_user_data: # 其他用户中选一个人, 看有没有评论过
if movie in user_data['MovieId'].unique(): # 如果评论过了
temp.append(user_data[user_data['MovieId'] == movie]['Rating'].values[0] / 5) # 就把第一次评分归一化后放进temp, 表示该用户对该电影的兴趣度
else: # 如果这个人没有评论过
temp.append(0) # 那这个人对这个电影的兴趣度就是0
# print(top_n_user_data)
# print(type(top_n_user_data))
interest = sum([top_n_users[i][1] * temp[i] for i in range(len(top_n_user_data))]) # 内循环之后, 其他所有人对这部电影的兴趣度的和, 就是target用户对这部电影的兴趣度
interest_list.append((movie, interest)) # 存一下电影和target用户对电影的兴趣度
interest_list = sorted(interest_list, key=lambda x: x[1], reverse=True) # target对所有电影的兴趣度都得到了, 降序排列, 输出前top_n个
return interest_list[:top_n]
def get_candidates_movies(self, target_user_id):
"""
get candidates movies
获得候选的电影
:param target_user_id:
:return: candidates movies
"""
target_movies = set(self.df[self.df['UserId'] == target_user_id]['MovieId']) # 存一下target用户点评的过电影, 去重
other_movies = set(self.df[self.df['UserId'] != target_user_id]['MovieId']) # 存一下其他用户点评过的电影
candidates_movies = list(other_movies - target_movies) # 取其他用户点评过而且target用户没有点评过的movies作为候选
return candidates_movies
def calculate(self, target_user_id=1, top_n=10):
"""
calculate top n movies for target user
:param target_user_id:
:param top_n:
"""
top_n_users = self.get_top_n_users(target_user_id, top_n)
# print(top_n_users)
candidates_movies = self.get_candidates_movies(target_user_id)
top_n_movies = self.get_top_n_movies(top_n_users, candidates_movies, top_n)
return top_n_movies
ItemCF(基于物品的协同过滤)
基于物品的协同过滤,主要是比较物品之间的相似度(具体是通过对每个用户都构造出一个Item-Item的矩阵,然后把所有矩阵叠加在一起)
class ItemCF:
def __init__(self, train):
self.train = train
@staticmethod
def list2dict(list_):
"""
list转为dic
:param list_: [(UserID, ItemID), (UserID, ItemID), ...]
:return: dic
"""
users = list(set([i[0] for i in list_]))
dic = dict(zip(users, [[] for i in range(len(users))]))
for key, value in list_:
dic[key].append(value)
return dic
def get_item_similarity(self):
"""
计算物体相似度
:param :
:return:
"""
c = dict() # 记录电影两两之间共同喜欢的人数
n = dict() # 记录电影的打分人数
print("计算物品相似度")
for user, items in tqdm(self.train.items()):
for item in items:
n[item] += 1 # item 被看的次数 +1
for item2 in items:
if item == item2:
continue
c[item][item2] += 1 # / math.log(1 + len(items) * 1.0) # 加入惩罚
w = dict()
for i, related_items in c.items():
for j, cij in related_items.items():
w[i][j] = cij / math.sqrt(n[i] * n[j])
LFM(隐语义模型)

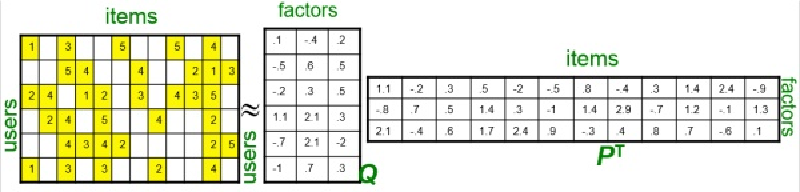
领域方法根本立足于统计,而LFM(隐语义模型)就开始向机器学习方向发展。根本思想是将原来简单的一个数变成一个高维的向量,向量的每一个元素都表示一种高层的含义,这种高层的参数是抽象的,对我们来说一般不具有可解释性(可以理解成加了一个中间层,就像一个小齿轮带动大齿轮,提高了精度)
import math
import numpy as np
class LFM:
def __init__(self):
pass
def RandomSelectNegativeSample(self, items, items_pool):
"""
随机选择一些负样本: 找热门但是不感兴趣
返回的ret是一个dict, 其中用户有过行为的item对应的value都为1,
然后有与数量相当的items_pool中但是没有行为的负样本value为0
:param items_pool: 候选物品的列表
:param items: 用户已经有过行为的物品的集合
:return: 筛选出不在用户行为物品集合中, 但是很热门(在候选物品中频率高)的物品集合
"""
ret = dict() # 维护用户有过行为的物品, 1为正样本, 0为负样本
for i in items:
ret[i] = 1
cnt = 0
# 需要注意的是,代码中的items_pool 为一个存储着所有items 的list,
# 因为有重复,所以每个物品被选中的概率和它出现的频率成正比。这就完成了选取热门物品的部分。
for i in range(0, len(items_pool) * 3):
item = items_pool[np.random.randint(0, len(items_pool))]
if item in ret.keys():
continue # 热门物品如果在用户行为中, 直接continue
cnt += 1 # 热门物品若不在用户行为中, 负样本加一
ret[item] = 0 # 记录value为0则是负样本
if cnt > len(items): # 控制负样本数量和正样本数量相等
break
return ret
def LatentFactorModel(self, user_item, F, N, alpha, flambda):
users_pool = []
items_pool = []
for user, items in user_item.items():
users_pool.append(user)
for item in items:
items_pool.append(item)
[P, Q] = self.InitModel(users_pool, items_pool, F)
for step in range(0, N):
for user, items in user_item.items():
samples = self.RandomSelectNegativeSample(items, items_pool)
for item, rui in samples.items():
eui = rui - self.Predict(P[user], Q[item])
P[user] += alpha * (eui * Q[item] - flambda * P[user])
Q[item] += alpha * (eui * P[user] - flambda * Q[item])
alpha *= 0.9
return P, Q
def Predict(self, Puser, Qitem):
"""
进行前向推理
:param Puser:
:param Qitem:
:return:
"""
res = np.sum(Puser * Qitem)
res = 1.0 / (1 + math.exp(-res))
return res
def InitModel(self, users_pool, items_pool, F):
Q = dict()
P = dict()
users_pool = set(users_pool)
items_pool = set(items_pool)
for user in users_pool:
P[user] = np.random.rand(F)
for item in items_pool:
Q[item] = np.random.rand(F)
return P, Q
def Recommend(self, user, P, Q):
rank = dict()
for item in Q.keys():
rank[item] = np.sum(P[user] * Q[item])
# ATTENTION! 相比于Predict, 这里没有归一化
return sorted(rank.items(), key=lambda x: x[1], reverse=True)[0:10]